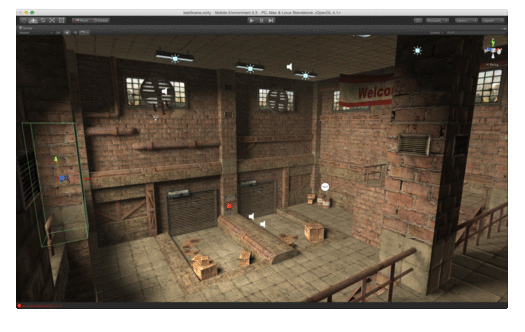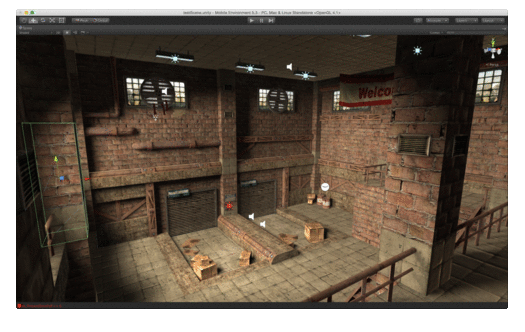
In part 1, we discussed the requirements and rationale behind Interior Mapping. In this second part, we’ll discuss the technical implementation of what I’m calling (for lack of a better title) “Tangent-Space Interior Mapping”.
Coordinates and Spaces
In the original implementation, room volumes were defined in object-space or world-space. This is by far the easiest coordinate system to work in, but it quickly presents a problem! What about buildings with angled or curved walls? At the moment, the rooms are bounded by building geometry, which can lead to extremely small rooms in odd corners and uneven or truncated walls!
In reality, outer rooms are almost always aligned with the exterior of the building. Hallways rarely run diagonally and are seldom narrower at one end than the other! We would rather have all our rooms aligned with the mesh surface, and then extruded inward towards the “core” of the building.

Curved rooms, just by changing the coordinate basis.
In order to do this, we can just look for an alternative coordinate system for our calculations which lines up with our surface (linear algebra is cool like that). Welcome to Tangent Space! Tangent space is already used elsewhere in shaders. Even wonder why normal-maps are that weird blue color? They actually represent a series of directions in tangent-space, relative to the orientation of the surface itself. Rather than “Forward”, a Z+ component normal map points “Outward”. We can simply perform the raycast in a different coordinate basis, and suddenly the entire problem becomes surface-relative in world-space, while still being axis-aligned in tangent space! A neat side-effect of this is that our room volumes now follow the curvature of the building, meaning that curved facades will render curved hallways running their length, and always have a full wall parallel to the building exterior.
While we’re at it, what if we used a non-normalized ray? Most of the time, a ray should have a normalized direction. “Forward” should have the same magnitude as “Right”. If we pre-scale our ray direction to match room dimensions, then we can simplify it out of the problem. So now, we’re performing a single raycast against a unit-sized axis-aligned cube!
Room Textures
The original publication called for separate textures for walls, floors, and ceilings. This works wonderfully, but I find it difficult to work with. Keeping these three textures in sync can get difficult, and atlasing multiple room textures together quickly becomes a pain. Alternative methods such as the one proposed by Zoe J Wood in “Interior Mapping Meets Escher” utilizes cubemaps, however this makes atlasing downright impossible, and introduces new constraints on the artists building interior assets.

Andrew Willmott briefly touched on an alternative in “From AAA to Indie: Graphics R&D”, which used a pre-projected interior texture for the interior maps in SimCity. This was the format I decided to use for my implementation, as it is highly author-able, easy to work with, and provides results only slightly worse than full cubemaps. A massive atlas of room interiors can be constructed on a per-building basis, and then randomly selected. Buildings can therefore easily maintain a cohesive interior style with random variation using only a single texture resource.
Finally, The Code
I’ve excluded some of the standard Unity engine scaffolding, so as to not distract from the relevant code. You won’t be able to copy-paste this, but it should be easier to see what’s happening as a result.
v2f vert (appdata v) {
v2f o;
// First, let's determine a tangent basis matrix.
// We will want to perform the interior raycast in tangent-space,
// so it correctly follows building curvature, and we won't have to
// worry about aligning rooms with edges.
half tanSign = v.tangent.w * unity_WorldTransformParams.w;
half3x3 objectToTangent = half3x3(
v.tangent.xyz,
cross(v.normal, v.tangent) * tanSign,
v.normal);
// Next, determine the tangent-space eye vector. This will be
// cast into an implied room volume to calculate a hit position.
float3 oEyeVec = v.vertex - WorldToObject(_WorldSpaceCameraPos);
o.tEyeVec = mul(objectToTangent, oEyeVec);
// The vertex position in tangent-space is just the unscaled
// texture coordinate.
o.tPos = v.uv;
// Lastly, output the normal vertex data.
o.vertex = UnityObjectToClipPos(v.vertex);
o.uv = TRANSFORM_TEX(v.uv, _ExteriorTex);
return o;
}
fixed4 frag (v2f i) : SV_Target {
// First, construct a ray from the camera, onto our UV plane.
// Notice the ray is being pre-scaled by the room dimensions.
// By distorting the ray in this way, the volume can be treated
// as a unit cube in the intersection code.
float3 rOri = frac(float3(i.tPos,0) / _RoomSize);
float3 rDir = normalize(i.tEyeVec) / _RoomSize;
// Now, define the volume of our room. With the pre-scale, this
// is just a unit-sized box.
float3 bMin = floor(float3(i.tPos,-1));
float3 bMax = bMin + 1;
float3 bMid = bMin + 0.5;
// Since the bounding box is axis-aligned, we can just find
// the ray-plane intersections for each plane. we only
// actually need to solve for the 3 "back" planes, since the
// near walls of the virtual cube are "open".
// just find the corner opposite the camera using the sign of
// the ray's direction.
float3 planes = lerp(bMin, bMax, step(0, rDir));
float3 tPlane = (planes - rOri) / rDir;
// Now, we know the distance to the intersection is simply
// equal to the closest ray-plane intersection point.
float tDist = min(min(tPlane.x, tPlane.y), tPlane.z);
// Lastly, given the point of intersection, we can calculate
// a sample vector just like a cubemap.
float3 roomVec = (rOri + rDir * tDist) - bMid;
float2 interiorUV = roomVec.xy * lerp(INTERIOR_BACK_PLANE_SCALE, 1, roomVec.z + 0.5) + 0.5;
#if defined(INTERIOR_USE_ATLAS)
// If the room texture is an atlas of multiple variants, transform
// the texture coordinates using a random index based on the room index.
float2 roomIdx = floor(i.tPos / _RoomSize);
float2 texPos = floor(rand(roomIdx) * _InteriorTexCount) / _InteriorTexCount;
interiorUV /= _InteriorTexCount;
interiorUV += texPos;
#endif
// lastly, sample the interior texture, and blend it with an exterior!
fixed4 interior = tex2D(_InteriorTex, interiorUV);
fixed4 exterior = tex2D(_ExteriorTex, i.uv);
return lerp(interior, exterior, exterior.a);
}
And that’s pretty much all there is to it! The code itself is actually quite simple and, while there are small visual artifacts, it provides a fairly convincing representation of interior rooms!

https://gfycat.com/FrankSoftAvocet
There’s definitely more room for improvement in the future. The original paper supported animated “cards” to represent people and furniture, and a more realistic illumination model may be desirable. Still, for an initial implementation, I think things came out quite well!