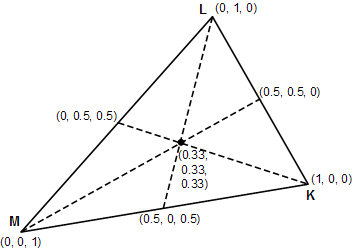
Isosurfaces are extremely useful when it comes to data visualization. From medical imaging to fluid flow analysis, they are an excellent tool for understanding complex volumetric data. Games have also adopted some of these techniques for their on purposes From the more rigid implementation in the ubiquitous game Minecraft to the Gels in Portal 2, these techniques serve the same basic purpose.
I wanted to try my hand at a general-purpose implementation, but before we dive into things, we must first answer a few basic questions.
What is an isosurface?
An isosurface can be thought of as the solution of a continuous function which produces a constant output in 3D. If you’re visualizing an electromagnetic field for example, you might generate an isosurface for a given potential, so you can easily determine its overall shape. This technique can be applied to other arbitrary values as well. Given CT scan data, a radiologist could construct an isosurface at the density of a specific type of tissue, extracting a 3D representation of bones or organs to view them separately, rather than having to manipulate a less intuitive stack of images.
What will we use this system for?
I don’t work in the medical field, nor would I trust the accuracy of my implementation when it comes to making a diagnosis. I work in entertainment and computer graphics, and as you would imagine, the requirements are quite different. Digital artists can already craft far better visuals than any procedure yet known; the real challenge is dynamic data. Physically simulated fluids, player-modifiable terrain, mechanics such as these present a significant challenge for traditional artists! What we really need is a generalized system for extracting and rendering isosurfaces in real time to fill in the gaps.
What are the requirements for such a system?
Given our previous use case, we can derive a few basic requirements. In no particular order…
- The system must be intuitive. Designers have other things to do besides tweaking simulation volumes and fiddling with configurations.
- The system must be flexible. If someone suggests a new mechanic which relies heavily on procedural geometry, it should be easy to get up and running.
- The system must be compatible. The latest experimental extensions are fun, but if you want to release something that anyone can enjoy, it needs to run on 5 year old hardware.
- The system must be fast. At 60 fps, you only have 16ms to render everything in your game. We can’t spend 10 of that drawing a special effect.
Getting Started!
Let’s look at requirement no. 4 first. Like many problems in computing, surface polygonalization can be broken down into repeated instances of much smaller problems. At the end of the day, the desired output is a series of interconnected polygons which appear to make up a complex surface. If each of these component polygons is accounted for separately, we can dramatically reduce the scope of the problem. Instead of generating a polygonal surface, we are now generating a single polygon, which is a much less daunting task. As with any discretization process, it is necessary to define a regular sample interval at which our continuous function will be evaluated. In the simplest 3D case, this will take the form of a regular grid of cells, and each of these cells will form a single polygon. Suddenly, this polygonalization process becomes massively parallel. With this new outlook, the problem becomes a perfect fit for standard graphics hardware!
For compatibility, I chose to implement this functionality in the Geometry Shader stage of the rendering pipeline, as it allows for the creation of arbitrary geometry given some basic input data. A Compute Shader would almost definitely be a better option in terms of performance and maintainability, but my primary development system is OSX, which presents a number of challenges when it comes to the use of Compute Shaders. I intend to update this project in the future, once Compute Shaders become more common.
If the field is evaluated at a number of regular points and a grid is drawn between them, we can construct a set of hypothetical cubes with a single sample at each of its 8 vertices. By comparing the values at each vertex, it is trivial to determine the plane of intersection between the theoretical isosurface and the cubic sample volume. If properly evaluated, the local solutions for each sample volume will form integral parts of the global surface implicitly, without requiring any global information.
This is the basic theory behind the ubiquitous Marching Cubes algorithm, first published in 1987 and still commonly used today. While it is certainly battle-tested, there are a number of artifacts in the output geometry that can make surfaces appear rough. The generated triangles are also often non-uniform and narrow, leading to additional artifacts later in the rendering process. Perhaps a more pressing issue is the sheer number of cases to be evaluated. For every sample cell, there are 256 possible planar intersections. The fantastic implementation by Paul Bourke wisely recommends the use of a look-up table, pre-computing these cases. While this may work well in traditional implementations, it crumbles under the parallel architecture of modern GPUs. Graphics hardware tends to excel at executing large batches of identical instructions, but begins to falter as soon as complex conditional branching is involved and operations have to be evaluated individually. In my tests, I found that the look-up tables performed no better, if not worse than explicit evaluation, as the complier could not easily expand and unroll the program flow, and evaluation could not be easily batched. Bearing this in mind, we ideally need to implement a method with as few logical branches as possible.
Marching Tetrahedra is a variant of the Marching Cubes algorithm which divides each cube into 5 (or 6 for a slightly different topology) tetrahedra. By limiting our integral sample volume to four vertices instead of 8, the number of possible cases drops to 16. In my tests, I got a 16x performance improvement using this technique (though realized savings are heavily dependent on the hardware used), confirming our suspicions. Unfortunately, marching tetrahedra can have some strange surface features, and has a number of artifacts of its own, especially with dynamic sampling grids.
Because of this, I ended up settling on naive surface nets, a simple dual method which generates geometry spanning multiple voxel sample volumes. An excellent discussion of the differences between these three meshing algorithms can be found here. Perhaps my favorite advantage of this method is the relative uniformity of the output geometry. Surface nets tend to be smooth surfaces comprised of quads of relatively equal size. In addition, I find it easier to comprehend and follow than other meshing algorithms, as its use of look-up-tables, and possible cases is fairly limited.
Implementation Details

The sample grid is actually defined as a mesh, with a single disjoint vertex placed at each integral sample coordinate. These vertices aren’t actually drawn, but instead are used as input data to a series of shaders. Therefore, the shader can be considered to be executed “per-voxel”, with its only input being the coordinate of the minimum bounding corner. One disadvantage commonly seen in similar systems is a fundamental restriction on surface resolution due to a uniform sample grid. In order to skirt around this limitation, meshing is actually performed. In projected space, rather than world space, so each voxel is a truncated frustum similar to that of the camera, rather than a cube. This not only eliminates a few extra transformations in the shader code, but provides LoD implicitly by ensuring each output triangle is of a fixed pixel size, regardless of its distance to the camera.
Once the sample mesh was created, I used a simple density function for the potential field used by this system. It provides a good amount of flexibility, while still being simple to comprehend and implement. Each new source of “charge” added to the field would contribute additively to the overall potential. However, this quickly raises a concern! Each contributing charge must be evaluated at all sample locations, meaning our shader must, in some way, iterate through all visible charges! As stated earlier, branching and loops which cannot be unrolled can cause serious performance hiccups on most GPUs!
While I was at it, I also implemented a Vertex Pre-pass. Due to the nature of GPU parallelism, each voxel is evaluated in complete isolation. This has the unfortunate side-effect of solving for each voxel vertex position up to 6 times (once for each neighboring voxel). The surface net algorithm utilizes an interpolated surface vertex position, determined from the intersections of the surface and the sample volume. This interpolation can get expensive if repeated 6 times more than necessary! To remedy this, I instead do a pre-pass calculating the interpolated vertex position, and storing it as a normalized coordinate within the voxel in the pixel color of another texture. When the geometry stage builds triangles, it can simply look up the normalized vertex positions from this table, and spit them out as an offset from the voxel min coordinate!
The geometry shader stage is then fairly straightforward, reading in vertex positions, checking the case of the input voxel, looking up the vertex positions of its neighbors, and bridging the gap with a triangle.
Was it worth it?
Short answer, no.
I am extremely proud of the work I’ve done, and the end result is quite cool, but it’s not a solution I would recommend in a production setting. The additional complexity far outweighs any potential performance benefit, and maintainability, while not terrible, takes a hit as well. In addition, the geometry shader approach doesn’t work nearly as well as I had hoped. Geometry shaders are notoriously cache-unfriendly, and my implementation is no exception. Combine this with the rather unintuitive nature of working with on-GPU procedural geometry in a full-scale project, and you’ve got yourself a recipe for very unhappy engineers.
I think the concept of on-GPU surface meshing is fascinating, and I’m eager to look into Compute Shader implementations, but as it stands, the geometry stage is not the way to go.
I’ve made the source available on my GitHub if you’d like to check it out!